Data analyses avec Tensorflow
Je rassemble ici une première passion pour le langage Python dans : PythonDiscovering: Python for dumies et le filtrage adaptatif ou prédictif qui me permettrait de faire des analyses judicieuses des cours de bourse.
J'ai travaillé sur le programme python :
PythonDiscovering/matPlot-005.py
Mais clairement cela n'est pas suffisant, il me faut aller plus loin dans la connaissance de TensorFlow de Keras et de leurs interactions.
Keras
C'est un système capable d'interfacer des backend comme JAX, TensorFlow ou PyTorch
MatplotLib
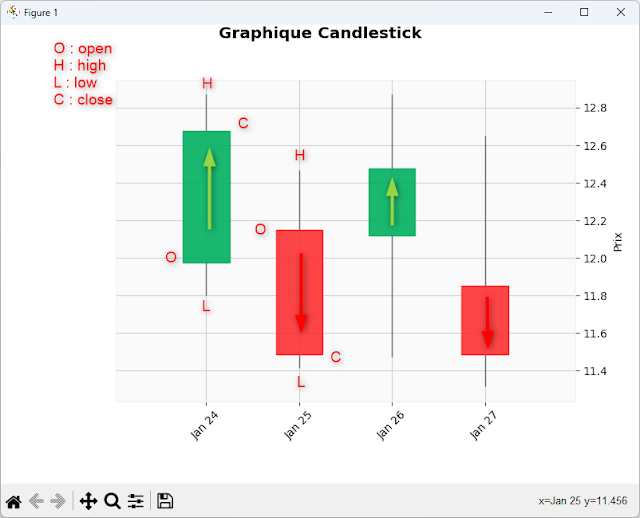
Faire de graphiques analyse des datas
Matplotlib 3.8.3 - Documentation
TensorFlow
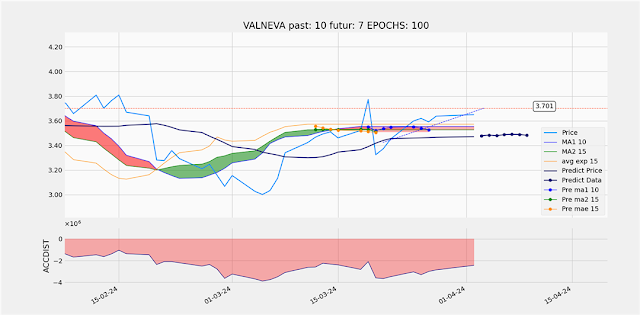
Je récupère et installe un ensemble d'algorithmes autour de TensorFlow pour réaliser des prédictions sur les cours de bourse.
Et puis j'ai demandé à ChatGpt d'expliquer de code de notre algorithme que je lui ai présenté et voici ses explications :
Ce code utilise un réseau de neurones à mémoire à long terme (LSTM) pour prévoir les données temporelles.
Voici une explication détaillée de chaque partie du code :
MinMaxScaler : Normalise les données entre une plage définie, ici entre 0 et 1.
Sequential : Permet de construire un modèle de réseau de neurones en ajoutant des couches de manière séquentielle.
Dense, Dropout, LSTM : Types de couches dans le réseau de neurones.
Normalisation des données : MinMaxScaler normalise y_data pour qu'elles soient comprises entre 0 et 1.
Préparation des listes x_train et y_train :
x_train contient des séquences de DAYS_IN_PAST jours.
y_train contient la valeur à prédire pour chaque séquence.
Conversion en tableaux NumPy : Pour faciliter l'entraînement du modèle.
Définition du modèle séquentiel.
Ajout de trois couches LSTM :
Chaque couche LSTM a 50 unités.
return_sequences=True pour les deux premières couches LSTM afin de renvoyer la séquence complète à la couche suivante.
Ajout de Dropout : Empêche le surapprentissage en désactivant aléatoirement une fraction des unités.
Dernière couche Dense : Prédit la valeur de sortie.
Compilation : Utilisation de l'optimiseur adam et de la fonction de perte mean_squared_error.
Entraînement : Le modèle est entraîné avec x_train et y_train sur un nombre d'epochs défini par EPOCHS avec une taille de batch de 32.
Concaténation des données : Création d'un ensemble de données total.
Préparation des données de test : Normalisation des données pour les tester avec le modèle.
Préparation des séquences de test : x_test est préparé de la même manière que x_train.
Prédiction des valeurs : Utilisation du modèle pour prédire les valeurs futures.
Inverse transformation : Conversion des valeurs normalisées prédites à l'échelle originale.
Préparation des données réelles : Extraction des dernières DAYS_IN_PAST valeurs pour faire des prédictions.
Boucle de prédiction :
Prédiction pour chaque jour futur.
Mise à jour de real_data pour inclure la nouvelle prédiction.
Inverse transformation : Conversion des valeurs normalisées prédites à l'échelle originale.
Ce code entraîne un modèle LSTM pour prédire les valeurs futures d'une série temporelle et utilise ce modèle pour faire des prédictions à court terme ainsi que des prédictions continues pour plusieurs jours dans le futur.
A quoi sert le paramètre EPOCH
Le paramètre `EPOCHS` dans le contexte de l'entraînement d'un modèle de réseau de neurones, y compris les modèles LSTM (Long Short-Term Memory), représente le nombre de fois que l'algorithme d'apprentissage va passer par l'ensemble complet de données d'entraînement.
### Explication détaillée
1. **Un epoch** : Un epoch signifie une itération complète à travers le jeu de données d'entraînement. En d'autres termes, pendant un epoch, chaque exemple du jeu de données est passé une fois à travers le réseau.
2. **Cycle de l'apprentissage** :
- **Avant l'entraînement** : Les poids du réseau de neurones sont initialisés (généralement de manière aléatoire).
- **Pendant un epoch** : Le réseau de neurones passe par chaque exemple de données d'entraînement, calcule la prédiction, évalue l'erreur par rapport à la valeur cible réelle (à l'aide d'une fonction de perte comme l'erreur quadratique moyenne), et met à jour les poids du réseau en fonction de l'algorithme de rétropropagation (utilisant un optimiseur comme Adam).
3. **Après plusieurs epochs** : L'objectif est que le modèle apprenne les caractéristiques et les relations des données d'entraînement, ce qui devrait conduire à une meilleure performance sur les nouvelles données (données de test ou données réelles).
### Importance de `EPOCHS`
- **Sous-entraînement** : Si `EPOCHS` est trop petit, le modèle n'aura pas assez de temps pour apprendre les relations complexes dans les données et peut sous-apprendre (sous-ajustement), ce qui signifie qu'il ne sera pas capable de capturer les motifs dans les données d'entraînement.
- **Sur-entraînement** : Si `EPOCHS` est trop grand, le modèle risque de trop apprendre (sur-ajustement) et de mémoriser les données d'entraînement, ce qui peut conduire à une mauvaise performance sur les nouvelles données car il ne généralise pas bien.
- **Point idéal** : Le but est de trouver un nombre de epochs optimal où le modèle a suffisamment appris pour bien prédire les nouvelles données, mais sans sur-ajustement. Cela est souvent déterminé par expérimentation et en surveillant des métriques de performance sur un jeu de validation.
### Exemple
Dans le code fourni :
```python
model.fit(x_train, y_train, epochs=EPOCHS, batch_size=32)
```
- **`epochs=EPOCHS`** : Spécifie le nombre de fois que le modèle va passer par l'ensemble des données d'entraînement `x_train` et `y_train`.
- **`batch_size=32`** : Le modèle va diviser les données d'entraînement en mini-lots de 32 exemples pour les mises à jour de poids.
### Conclusion
Le paramètre `EPOCHS` contrôle le nombre de passes complètes à travers le jeu de données d'entraînement, influençant directement la capacité du modèle à apprendre à partir des données. Un nombre approprié d'epochs est crucial pour l'équilibre entre l'apprentissage suffisant et la généralisation correcte du modèle.
Et sur le paramètre batch_size=32
Voici quelques points clés à considérer pour déterminer si batch_size=32 est optimisé :
1. Impact de la Taille du Batch
Taille de Batch Petite : Peut fournir une estimation plus bruyante du gradient mais peut aider à sortir des minima locaux. Elle offre une plus grande régularisation, ce qui peut améliorer la généralisation.
Taille de Batch Grande : Fournit une estimation plus précise du gradient mais nécessite plus de mémoire et peut converger plus rapidement. Cependant, elle peut parfois entraîner un sur-ajustement.
2. Considérations Pratiques
Mémoire GPU : Une taille de batch plus grande peut nécessiter plus de mémoire, ce qui peut être une limitation si vous utilisez des GPU avec des capacités mémoire limitées.
Temps d'Entraînement : Des tailles de batch plus grandes peuvent accélérer le temps d'entraînement par epoch mais peuvent nécessiter plus d'epochs pour converger.
Stabilité du Gradient : Les tailles de batch plus petites peuvent entraîner une instabilité dans les mises à jour des poids, ce qui peut parfois ralentir la convergence.
3. Essais et Erreurs
Souvent, le choix optimal de la taille de batch nécessite des expérimentations. Il est courant d'essayer différentes tailles de batch et de comparer les performances.
4. Recherche Empirique
Des recherches empiriques ont montré que des tailles de batch de 32 ou 64 sont souvent de bons points de départ. Cependant, des tailles de batch plus grandes comme 128 ou 256 peuvent également être efficaces, en fonction des données et des ressources disponibles.
Exemple d'Expérimentation
Voici comment vous pourriez expérimenter avec différentes tailles de batch :
batch_sizes = [16, 32, 64, 128]
best_batch_size = 32
best_loss = float('inf')
for batch_size in batch_sizes:
model = Sequential()
model.add(LSTM(units=50, return_sequences=True, input_shape=(x_train.shape[1], 1)))
model.add(Dropout(0.3))
model.add(LSTM(units=50, return_sequences=True))
model.add(Dropout(0.3))
model.add(LSTM(units=50))
model.add(Dropout(0.3))
model.add(Dense(units=1))
model.compile(optimizer='adam', loss='mean_squared_error')
model.fit(x_train, y_train, epochs=EPOCHS, batch_size=batch_size, verbose=0)
val_size = int(len(x_train) * 0.2)
x_val = x_train[-val_size:]
y_val = y_train[-val_size:]
score = model.evaluate(x_val, y_val, verbose=0)
if score < best_loss:
best_loss = score
best_batch_size = batch_size
print(f'The best batch size is: {best_batch_size} with a validation loss of: {best_loss}')
Il faudra essayer ...


Commentaires
Enregistrer un commentaire